
Back in the day when I was studying computer vision, I played around with computational steganography. This is the art of concealing information in images in a way that couldn’t be seen by the human eye or detected by machine learning. This included, amongst other things, subtly altering the data contained in pixels to include an extra byte or two or adding visually invisible noise that, when extracted, contained a message. The motivation for this was twofold. Firstly, it was about learning how computational images work and what you could do with them. Secondly, it was all about creating stories about clandestine spies and espionage. This was the storyteller driving the technologist.
Outside the learning context, the resulting images are known as “adversarial images”; that is, the images that have been perturbed (altered) in a way that fools machine learning models to incorrectly classify or identify them. The famous image of the panda being classified as a gibbon first appeared in a 2015 paper by Goodfellow et al. (Goodfellow et al., 2015).
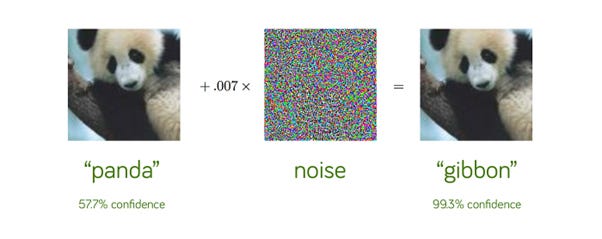
The consequences of AI models being unable to correctly classify images are severe. Consider medical imaging, where cancers are misdiagnosed. Or, imagine in the near future you are traveling in your autonomous vehicle. Driving down the road you pass a hoarding covered with a famous Banksy mural of a girl holding a red balloon. Suddenly your car speeds up, makes a sharp left and collides with a wall because it incorrectly classified the artwork as a road sign.
Intentionally inserting adversarial images (or any harmful or misleading data) into training data is referred to as data poisoning. The goal is to corrupt the model’s learning process, causing it to make errors or behave unpredictably. The potential harms caused by this behaviour are clear enough. Or are they?
Roll forward to 2024 and another scenario involving data poisoning has emerged, not as a malicious act but as an act of self-defence.
While artificial intelligence continues to revolutionize creative industries, the balance of power between artists and AI companies has been increasingly skewed. With the advent of advanced generative models, artists’ works are frequently scraped from the internet without consent, becoming part of massive datasets that fuel these AI systems. Even when artists use methods such as opt-out lists and do-not-scrape directives, these are often ignored by AI companies hungry for data.
Let me introduce Nightshade (Shan et al., 2024), a prompt-specific poisoning tool developed by researchers at the University of Chicago, which offers a new line of defence for artists. Nightshade potentially represents a significant leap in protecting artists’ rights. By allowing artists to subtly alter their digital works, it creates poisoned samples that look identical to the original images to human viewers but which cause AI models to misinterpret them. When these poisoned samples are incorporated into training datasets, they can disrupt the AI’s ability to generate accurate images based on specific prompts. For instance, an AI model trained on poisoned images might generate a picture of a cat when prompted to create an image of a dog.
The tool’s ability to corrupt model outputs with as few as 100 poisoned samples is groundbreaking. It challenges the previous belief that generative models, trained on billions of images, were impervious to data poisoning attacks. Nightshade’s effectiveness lies in its exploitation of “concept sparsity.” Concept sparsity refers to a situation where specific concepts or prompts are represented by only a small number of samples in a large dataset. This limited representation makes it easier for targeted attacks to manipulate the model’s understanding of these concepts.
The question is, do we want to go down a path that pits artists against companies, people against machines, in some sort of data arms race? Given the potential of what AI can deliver as well as the harms it can cause — its undeniable potential for dual use — can we really afford to foster an environment that leaves people no real alternative than to poison data that we may come to rely on for our well-being and safety? Can we contemplate consigning artists to the extinction list because they are unable to make a living from something that is so fundamental to our culture, identity, and collective imagination?
Nightshade — a Canary in the Coal Mine
Nightshade does more than introduce a moral and ethical discussion. It is a canary in a mine, and it is telling us that all is not well. The rise of Nightshade highlights the urgent need for a re-evaluation of how we manage and protect digital content in the age of AI. This small but powerful tool is a symptom of a larger problem: the imbalance of power between creators and the corporations that profit from their work.
The creation of tools like Nightshade signals a growing frustration among artists. They are no longer willing to passively accept the unauthorized use of their work. Instead, they are taking matters into their own hands, using technology to fight back. Unlike the Luddites, who famously sabotaged looms by throwing their wooden shoes, or “sabots,” into the machinery to halt the progress of industrialization, artists using Nightshade are not attempting to destroy technology. Rather, they are leveraging technology itself to protect their rights and ensure fair treatment. This is not a revolt against progress but a demand for ethical practices and respect in the digital age.
Nightshade and similar tools bring to light significant concerns about the integrity of data used to train AI models. When artists — or anyone — poison datasets to protect their intellectual property, it raises critical issues about the viability of AI as it currently exists.
If datasets are corrupted, the efficacy of AI models diminishes. They become less reliable and more prone to errors, which can have serious consequences, especially in sensitive applications like healthcare, autonomous driving, and security. Moreover, if those who generate the data needed to train models with integrity are properly remunerated (and they should be), then the cost of training large models becomes prohibitive (and they are already incredibly expensive).
Perhaps it’s time to more actively inquire and question the current paradigm of training AI models that are so reliant on massive datasets scraped from the internet. If the machine learning maths geniuses are short of ideas on how to do this, maybe they could ask the artists. After all, artists have been dealing with the complexities of creativity, ownership, and value for centuries. They understand the importance of context, nuance, and integrity in ways that algorithms currently do not.
References
Goodfellow, I. J., Shlens, J., & Szegedy, C. (2015). Explaining and Harnessing Adversarial Examples. arXiv preprint arXiv:1412.6572. Available at: https://arxiv.org/abs/1412.6572
Shan, S., Ding, W., Passananti, J., Wu, S., Zheng, H., & Zhao, B. Y. (2024). Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models. arXiv preprint arXiv:2310.13828. Available at: https://arxiv.org/pdf/2310.13828